Java 集合简述
Java 的集合由两个接口实现:Map 和 Collection
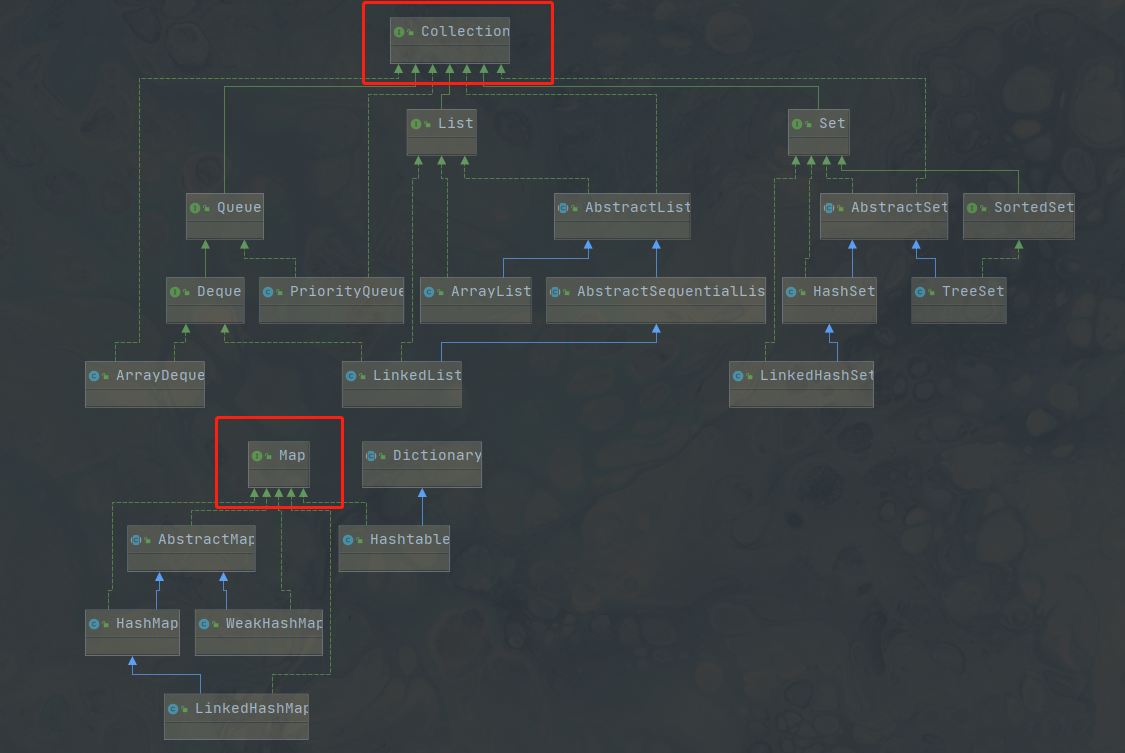
Collection 和 Map 最大的区别就是:
Map存key-value键值对Collection只存放一个
Map

key-value 键值对,不重复
Map 接口本身定义了很多方法,一些基本的不多说
容易忽略的是
computemerge
merge:
merge 方法是 1.8 才加进来的。
- 第三个参数是
BiFunction函数式接口,用来定义规则
1 | default V merge(K key, V value, |
使用:
1 | Map<String, Integer> map = new HashMap<>(); |
compute:
1 | Map<String, Integer> map = new HashMap<>(); |
HashMap
HashMap
- 确定下标
- 插入
- 扩容/初始化
Collections.SynchronizedMap
线程安全
内部维护了一个普通对象 Map,还有排它锁 mutex
操作 map 的时候,就会对方法上锁
1 | private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable { |
1 | public int size() { synchronized (mutex) {return m.size();} } |
Hashtable
- Hashtable 继承了 Dictionary,而 HashMap 继承的是 AbstractMap
- HashMap 的初始容量为 16,Hashtable 初始容量为 11,负载因子默认都是 0.75f
- 当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1
线程安全
1 | public synchronized V get(Object key) { |
Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null
Hashtable 在 put 空值的时候会直接抛空指针异常
1 | public synchronized V put(K key, V value) { |
HashMap 做了特殊处理
1 | static final int hash(Object key) { |
ConcurrentHashmap 和 Hashtable 都是支持并发的,这样会有一个问题,当你通过 get(k) 获取对应的 value 时,如果获取到的是 null 时,你无法判断,它是 put(k,v) 的时候 value 为 null,还是这个 key 从来没有做过映射
HashMap 是非并发的,可以通过 contains(key) 来做这个判断
而支持并发的 Map 在调用 m.contains(key) 和 m.get(key),m 可能已经不同了
contains(key) 也是可以使用 synchronized 进行同步的,所以调用 contains(key) 得到的就是该线程本时刻 map 的状态,本身不存在歧义
问题的关键在于多线程情况下,即便通过 contains(key) 知晓了是否包含 null,下一步当你使用这个结果去做一些事情时可能其他线程已经改变了这种状态,这在单线程下是不可能发生的
并发环境下,如果 contains(key)了,得到的结果之后,再利用这个结果进行逻辑处理,可能由于其他并发线程的执行,导致该条件不成立
摘自stackoverflow:
Hashtable 是较古老的类,通常不鼓励使用它。 在之后的使用中,设计人员发现开发中通常需要一个空键或者空值,于是就在HashMap中增加了对null的支持。
HashMap作为HashTable之后实现的类,具有更高级的功能,这基本上只是对Hashtable功能的改进。 创建HashMap时,它专门设计为将空值作为键处理并将其作为特殊情况处理。
补充:JDK源码中作者的注释:
To successfully store and retrieve objects from a Hashtable, the objects used as keys must implement the hashCode method and the equals method
要从Hashtable成功存储和检索对象,用作键的对象必须实现hashCode方法和equals方法。
由于null不是对象,因此不能在其上调用.equals()或.hashCode(),因此Hashtable无法将其计算哈希值以用作键
ConcurrentHashMap
ConcurrentHashMap
Collection
Colletion 接口定义了方法,无非就是 CRUD,好像也没有 U
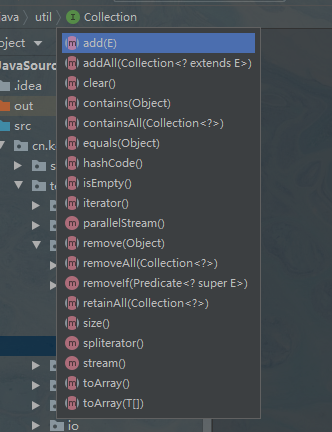
注意还有一些 api:
isEmpty:判断集合是否为空size:集合大小toArray:集合 => 数组
List
List 是 有序 的、可重复 的
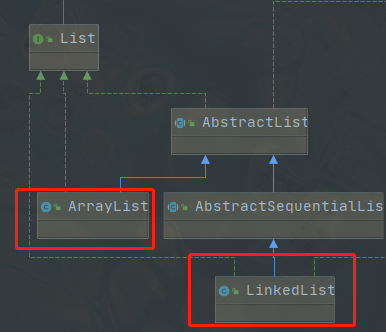
实现常用的有:ArrayList 和 LinkedList,从字面意思就能知道它们底层的数据结构
void replaceAll(UnaryOperator<E> operator)```java
ArrayListlist = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);list.replaceAll(t -> t + 1);
list.forEach(System.out::print); // 234
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
### Set

`Set` 的特点是 **无序**、**不重复**
底层即是 Map,只是值字段不用
`AbstactSet` 定义了一些共有的方法:

实现主要是 `TreeSet`、`HashSet`、`LinkedHashSet`
- `HashSet`: 底层就是 `HashMap`
- ```java
private transient HashMap<E,Object> map;
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
TreeSet:底层TreeMap,红黑树,实现了NavigableSet接口,NavigableSet实现了SortedSet接口,SortedSet使得他有序,SortedSet的实现也就他一个LinkedHashSet:在HashSet的基础上,每个元素都额外带了一个链记住下一个添加的元素,以此来维护顺序
快速失败
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了增加、删除、修改操作,则会抛出 ConcurrentModificationException
- 迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变 modCount 的值。每当迭代器使用 hashNext()/next() 遍历下一个元素之前,都会检测 modCount 变量是否为 expectedmodCount 值,是的话就返回遍历;否则抛出 ConcurrentModificationException 异常,终止遍历
这里异常的抛出条件是检测到 modCount != expectedmodCount 这个条件
如果集合发生变化时修改 modCount 值刚好又设置为了 expectedmodCount 值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的 bug
java.util 包下的集合类都是快速失败的,不能在多线程下发生并发修改( 迭代过程中被修改 )
失败安全
采用失败安全机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历
- 由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发 ConcurrentModificationException
基于拷贝内容的优点是避免了 ConcurrentModificationException,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。这也就是他的缺点,同时,由于是需要拷贝的,所以比较吃内存
java.util.concurrent 包下的容器都是安全失败,可以在多线程下并发使用,并发修改